
Livrem og seler plejer at give en ekstra sikkerhed, og det var med den bagtanke, at en webmaster for ikke så længe siden valgte at løse et duplicate content problem med en – troede han – sindig brug af en kombination af Canonical URL tag og “noindex. Men det skulle vise at være en alt andet end heldig “forsikring”. Godt nok blev duplicate content problemet løst – men ikke helt på den måde, det var ønsket. Det blev løst, fordi Google ganske enkelt fjernede både den canonicale URL og alle de underliggende i et snuptag. Og det kostede dyrt, for der var tale om sider på 1. pladser med en meget høj omsætning. Men hvad var det egentlig, der gik galt?
Baggrunden
Lad os starte med begyndelsen – det er nu engang en smart ting at gøre. Der er tale om en webshop, der sælger højt profilerede brands. For nogle af disse brands vedkommende er der så mange varer, at produktoversigten er opdelt over op til 6-7 sider.
Den grundlæggende URL (den canonicale) så således ud: shopnavn.dk/brand-betegnelse/ og de underliggende URLs er så dannet efter denne model: shopnavn.dk/brand-betegnelse/?page=2, shopnavn.dk/brand-betegnelse/?page=3 osv.
Selve siden er opbygget som skitseret med min barnlige streg herunder. Den beskrivende tekst om brandet i de grønne felter går igen på samtlige undersider:
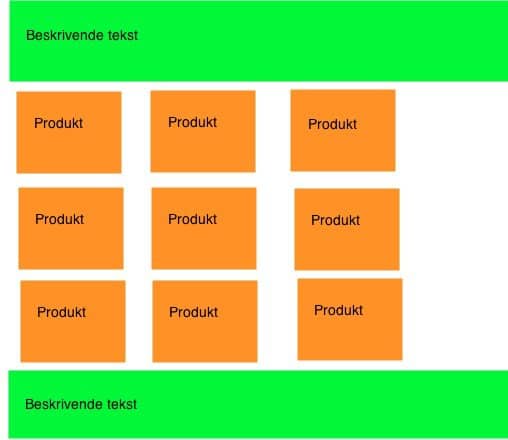
Dette er jo en helt klassisk og fremragende opbygning – hvis der kun er én side. Men når der er flere sider som i tilfældet her, er det den sikre vej i duplicate content problemer, for tekstmæssigt er alle varianterne (/?page=2, /?page=3 osv.) ganske ens. Det er kun produktbillederne og den nærmest ikke eksisterende tekst til hvert af produkterne, der varierer.
For at undgå duplicate content valgte webmasteren at sikre sig med et canonical tag, der henviste til shopnavn.dk/brand-betegnelse/ på alle siderne. Helt efter bogen og med den ønskede virkning.
Men sikkerhed er jo en god ting, og derfor valgte den omhyggelige webmaster at tilføje “noindex/follow” på alle undersiderne – altså på /?page=2, /?page=3 osv. Dette baseret på læsning af “eksperters” sikkert velmente råd.
I princippet burde den jo holde vand og yde et ekstra bolværk mod duplicate content. Med den sag på plads sov webmasteren roligt om natten – lige til han en dag vågnede og konstaterede, at hans ekstremt givtige nr. 1 placeringer på de meget stærke brands var forsvundet. Og ikke bare røget ned i placering – næ de var ganske enkelt forsvundet fra indeks!
Fejl i Googles håndtering eller logisk konsekvens?
Den gode webmaster kontaktede mig og bad om hjælp – og jeg tog et kig på sagen. Mit første indtryk var dyb undren, for der er tale om et yderst velbygget site uden tekniske fejl eller uhensigtsmæssigheder. Der er ingen robots.txt på sitet, der kunne give problemer. Der var ikke cloaket noget, og selv en meget minutiøs gennemgang af kildekoden på hver af hovedsiderne afslørede intet andet end godt håndværk.
Det var lige før, jeg skulle til at bede til de algoritmiske Guder – for der var bare ikke noget galt med de der landingssider. I bare desperation tjekkede jeg kildekoder på de underliggende, og der fandt jeg så den der “noindex/follow” i hver af dem. Så var det at tanke slog ned i mig: Hvad nu, hvis Google tager værdien af “noindex” med over på den canonicale side?
Altså: Vi har en URL, der hedder shopnavn.dk/brand-betegnelse/?page=3 og i head på den står der et canonical tag, der siger <link rel=”canonical” href=”http://shopnavn.dk/brand-betegnelse/” /> og en “meta name robots”, der siger “noindex/follow”. Kunne det virkelig tænkes, at Google tager den “noindex” værdi med fra /?page=3 og over på den canonicale URL?
Jeg var noget i tvivl – for på den ene side lød det helt vanvittigt, men på den anden side var der en vis indre logik i det. Jeg fik min nye kunde til at fjerne “noindex/follow” på alle undersiderne – og så var der bare at vente.
Ventetiden blev kort. Efter to døgn var de tilbage på de gamle placeringer. Og der blev ikke foretaget andet overhovedet end at fjerne “noindex/follow” på undersiderne. Jeg tør derfor godt drage konklusionen, at den omtalte konstruktion medførte en deindeksering. Dette bakkes op af, at samtlige de brandsider, hvor der IKKE er paginering, overhovedet ikke blev ramt.
Google har altså taget meldingen om “noindex” på undersiderne og overført den til den canonicale URL.
Om det er sådan, Google har skruet det sammen bevidst, eller om der er tale om en fejl, har jeg ikke kunnet finde entydige svar på. Men i forhold til denne sag er det også ligegyldigt.
Nu ved du, at du skal passe på. Lad være med at sætte “noindex” ind på URLs, du allerede har angivet en canonical URL for.
Og det var det, jeg lige ville dele med dig.
Rosenstand out!
Det var kattens. Godt spottet! Det var da virkelig godt du lokaliserede problemet hurtigt nok til at genvinde placeringerne. Thanks for sharing!
Hej Thomas
Tak for advarslen! Den fælde kunne jeg sagtens være røget i.
Jeg kom til at tænke på, har du nogle erfaringer endnu med de nye rel=prev/next tags? Jeg læste om dem på http://googlewebmastercentral.blogspot.com/2011/09/pagination-with-relnext-and-relprev.html, og det ser ret smart ud, men findes der nogle erfaringer med, om de virker efter hensigten? Det er jo altid vanskeligt med de tags, som ikke garanterer en effekt, men som blot er en “hensigtserklæring”.
Tak for et fedt indlæg!
Hej Morten
Jeg har indtil nu kun set positiv effekt af rel=next/prev tagget. Men det udelukker jo ikke, at der kan være komplikationer med det også.
Det var godt nok en interessant opdagelse du der har gjort. Jeg skal i hvertfald have sat noget validering på mit CMS der gør, at man ikke kan bruge canonical url og noindex samtidig, det kan jo gå helt galt. Tusinde tak for at dele din opdagelse.
Mon ikke problemet skyldes at Google løbende følger hjemmesiden og automatisk indexer den senest opdaterede side?
Hvis den nyeste side siger “nofollow”, så er det ligesom en slukket kontakt. Der skal nogen til at trykke på knappen, der siger “follow”
Er det ikke lidt ulogisk at gentage det samme indhold øverst på 5 sider i rækkefølge? Hvis jeg har forstået det rigtigt, er det netop den øverste del af dokumentet, som Google og andre robotter kigger på.
Prøv at kigge på Google Søgeindsigt (Google-søgning)
Hej Karsten
Næ – det er der egentlig ikke noget ulogisk i under forudsætning af, at man sætter canonical tag på. Mange CMS er bygget sådan – faktisk er alle shopsystemer sådan.
Sagen er også lidt relateret til det eksperiment som Grosen Friis kører på E-Universe lige nu, om man kan parse linkværdi igennem sider der har canonical tag, og dermed foretage PR Sculpting den vej igennem. Hvilket jeg ikke ville kunne fortså hvis man kunne. Rent logisk giver det ingen mening, men det jo lige meget hvad der er logisk, det handler om hvad der virker.
For mig at se virker det som en bug på canonicaltagget, men det kan man så udnytte , den anden vej rundt.
Jeg må lige ind på E-Universe og se om den kære Grosen, har fundet ud af mere, siden sidst jeg var der 🙂
Hej Thomas
Tak for tippet, det skal der helt sikkert lige tjekkes op på
Mvh
Morten
Fuck en spøjs case og en endnu mere spøjst resultat!
Gad vide hvad der ser hvis man peger cannonical mod konkurrenten i stedet 🙂
Uha Frederik – jeg vælger at tro på, at der er lukket for det med cross domain canonical. Men der testes lige nu.
Hmm håber Google har tænkt den godt igennem… Matt Cutts sagde følgende i april 2011: http://bit.ly/j7Obrb 🙂
Ja lad os håbe det. Men vi er et par stykker, der tester lige nu, så svaret dukker nok op lige pludselig.
Jeg har længe benyttet “noindex” fra og med side 2 på alle pagede kategorisider (dog uden brug af canonical-elementet) – hidtil har jeg ikke oplevet problemer med den metode.
Det er helt bevidst, at jeg har holdt mig fra at bruge canonical-elementet, da jeg før har oplevet utilsigtede effekter ved brug af elementet.
I øvrigt har Demib for et par år siden (af flere omgange) været ude med riven i forhold til canonical-elementet: http://www.demib.dk/canonical-tag-1057.html
Næ Jesper – det skulle du heller ikke gerne. Det er kombinationen af noindex og canonical, der har lavet balladen i det omtalte eksempel.
Jeg forstår så ikke, hvorfor du ikke benytter canonical i stedet for noindex? Du får jo ikke hentet linkjuice ind på den canonicale side med den metode, du bruger.
At nogle promiller af verdens SEO folk ikke bryder sig om canonical elementet gør det ikke mindre effektivt. Husk blot på, at canonical tag er et plaster på ikke optimale løsninger. Det bedste er lade sorteringer, pagineringer etc. ske client side i stedet for server side.
Hvis man har mange sider, altså +100 ved f.eks. et sitemap, så er det vel bedst at køre det server side, eller er det ikke et issue længere med mange links på en side (som det jo vil være hvis det køres client side)?
Det betyder mindre i dag. Google har også meldt ud at +100 links på en URL er fint.
Det skyldes, at jeg ikke er 100% klar over effekter og bivirkninger ved canonical-elementet.
Men nu vil jeg da lave lidt tests med elementet.
Jeg vil i den sammenhæng helt bruge canonical af hensyn til linkjuicen.
Der skulle have stået “helst” 😉
Jeg blev også ret imponeret da jeg læste dit indlæg – utrolig godt spottet! Jeg skal selv i gang med at arbejde med følgende og faktisk havde tanken omkring at bruge canonical og noindex stræfet mig.
Tak for advarelsen og godt spottet 🙂
Hej Thomas
Tak for advarelsen, er spændt på at høre jeres resultat på testene. Det må være sådan noget som det du har spottet, der gør forskellen på en god seomand og en der tror han er seomand;-)
God jul til jer derover.
Frank Eskelund
Hej Thomas
Vi har 2 kunder der har valgt at kører med både canonical og noindex,follow. Har lige tjekket op på dem og de har begge deres “første sider” indekseseret.
Hej Jacob
Jeg kendte engang en fyr, der havde kørt spritkørsel mange gange, uden der skete noget. Det ændrer nu ikke på, at det er farligt 😉
Hvis I lader de to kunder fortsætte med det setup så lad os høre, hvordan det spænder af, ikke?
Hmm, ja egentlig skulle man jo mene at den enten reagerer på det, eller ikke gør.
Lad os endelig høre hvad der sker, eller ikke sker. 🙂
Hej Thomas
Spændende indlæg. – Jeg synes nu ikke det er 100 % logisk med konsekvensen, men på den anden side kunne man sagtens forestille sig. – Det kunne være spændende at lave nogle tests på i hvert fald. Men du har sikkert ret.
Spooky. Og svært at se, hvorfor det skulle give mening for Google.
En tanke kunne være den interne link building. /brand/-siden har måske 1 link fra hovednavigationen samt links fra alle undersiderne. Når undersiderne fjernes fra indekset, så ryger der “en masse” links til /brand/-siden, mens sidebladringsfunktionerne (paginering på dansk) på /brand/-siden har links til alle undersiderne.
Ikke super logisk, men det kan måske have skabt midlertidig forvirring omkring relevansen af de enkelte sider. Måske problemet kunne være undgået, hvis der var nofollow på pagineringslinkene fra /brand/-siden. Så ryger indekseringen af de enkelte produkter nok, men det gør den vel også, hvis page=-siderne får en noindex.
Du skal ikke bruge nofollow på interne links. Det er en skidt ide, som jeg kraftigt vil advare mod. Og det ville heller ikke have nogen effekt i dette tilfælde alligevel. Tjek evt. denne fra Matt Cutts: Video
Det er jo ærgerligt, at man ikke kan bruge nofollow, blot fordi det er blevet misbrugt. Google kunne jo spare krudt på at respektere det og sige, “så undlader vi at følge det link”. Det ville spare dem noget energi på crawling af sider. Formålet ville netop ikke være pagerank sculpting, men blot at sige, at de ikke skulle kigge der.
Der er i øvrigt en gammel diskussion her (http://www.google.com/support/forum/p/Webmasters/thread?tid=79b4544fb7e1cb3c&hl=en), hvor det nævnes, at noindex ikke skal bruges sammen med canonical – dog fra en vinkel, hvor det gælder sider, der endnu ikke er indekseret.
Hej Thomas
Super interessant observation, og absolut ikke en effekt man umiddelbart ville forvente. Jeg læste et eller andet sted at Google anbefalede at man kun bruger eet tag til at resolve DC issues. Her er et andet link der berører emnet (omend det ikke forklarer det du har observeret). Det kan være en designfejl i algoritmen du har været vidne til:
http://www.seroundtable.com/archives/020151.html
Credits til Frederik for idden om at bruge det cross-domain 😉
Hej Thomas,
Noget nyt “i sagen”? Er der nogen indikationer af dine tests? Eller er det endnu for tidligt at sige noget om?
dbh
Kenneth
Hej Kenneth
Jeg har lykkedes med at få én ud af tre URLs deindekseret med metoden – de to andre er fortsat i indeks. Så helt entydigt tør jeg svare endnu.
Spændende! Så er der jo nok noget om snakken. Ikke bare en “enlig svale”
dbh
Kenneth
Av for en giftig cocktail, jeg har faktisk været tæt på at gøre nøjagtigt det sammen. I hvert fald tak fordi du deler det.
Hej Thomas! (og glædelig jul)
Jeg har flere gange i din tekst læst: noindex/follow” Skal der stå ‘follow’ eller er det ikke nok med ‘noindex’ for at få samme effekt.
Jeg har set her og der, hvor begge metoder er anvendt, og er derfor lidt forvirret.
Mvh. John
Når du sætter noindex på en URL, skal du have follow med, hvis du vil være sikker på, at bots følger de links, der er på siden.
Hej Thomas
Jeg har et spørgsmål som jeg håber på at du kan svare på, først og fremmest dejlig post fra dig. Jeg nyder det, og jeg kan godt se det er et problem at overføre Noindex videre, tak!
Nu til spørgsmålet:
Hvis jeg har 3 vare; Henholdsvis:
webshop.dk/alufaelge17
webshop.dk/alufaelge18
webshop.dk/alufaelge19
De har alle 3 samme tekst på siden, det eneste der er forskelligt er 17,18 og 19 tommer. Hvad er dit bedste råd, at bruge callink på en speciel måde, eller omskrive alle 3 tekster til unikke?
Hej Emil
Som med det meste andet i SEO (og modsat det indtryk man kan få på f.eks. Amino), er det mere nuanceret end som så.
For at give et kvalificeret svar, er det nødvendigt at vide, om der er et interessant antal søgninger på de specifikke fælgstørrelser på det pågældende brand.
Er der det, kan det tale for tre unikke sider, der tekstmæssigt er så forskellige, at der ikke kan dømmes “redundans” af Google. Og med tilpasse sidetitler etc.
Hvis der ikke er, vil det nok være det smarteste enten:
– at benytte canonical URL tag, så én af de tre størrelser er den kanoniske
eller
– lave én side med alle tre størrelser på, og lade brugerens valg ske server side, så der ikke genereres en URL for hver størrelse.
Okay, Mange tak for svaret. Det var en god forklaring.
Hej Thomas,
Jeg ved godt at det er ved at være et ældre indlæg, men jeg sidder med en problemstilling, der er meget lig den Emil Sørensen beskriver.
Hvad er grunden til at du ville benytte canonical tags fremfor noindex i hans tilfælde?
Hej Jesper
Af den simple grund, at det ville være dumt at benytte noindex. Ved at benytte Canonical tag får du jo overført evt. værdi af indgående links til undersiderne til den kanoniske URL – det gør du ikke med et noindex.
Gammel tråd, men tak for relevant info! Den bliver lige skrevet bag øret i tilfælde af at der skal håndteres paginerede sider.